The network of an EHR system has two main purposes:
Availability Ensuring that healthcare staff have access to the right data when they need it.
Robustness Allowing the network to recover from loss of functionality, to maintain availability without data loss.
Networks come in three basic types, as defined by Alexander Galloway, in his book Protocol (2004)
Centralised
Centralised networks are the most basic type of network, a collection of nodes connected to a central node, or hub. A common example is radio - a single station broadcasts to many clients. The central hub holds power over all connected clients, and is a weak point of failure. Most existing EMR systems in New Zealand work like this - a single computer will be set up as a server in the doctor's office, and the doctor's computers will connect to it to share the records.
Decentralised
Decentralised networks are essentially a duplication of centralised networks - there is still central nodes, they are just duplicated. The benefit is that if the central node fails, there are others to take its place. Alexander argues control exists in these networks through bureaucracy. The central nodes have to be run by a small group of people, and they have the ultimate say of what the network is used for.
There are decentralised networks used in New Zealand for healthcare, such as the several 'Shared Care' record systems within New Zealand - SharedCareRecord, Whānau Tahi and HealthOne.
These services are is a service allow part of your medical record to be uploaded to a central cloud platform. The record can be accessed in specific cases, for example if you visit a different GP, if you're in an emergency department / after-hours practice, or in an ambulatory setting by paramedics.
Distributed
Distributed networking is the type I'm most interested in. In a distributed network, there is no defined hierarchy - any node can connect to any other node, or not. No node holds any inherent power over any other, and the nodes can re-arrange themselves free of restriction. The distributed networks of our time have been the most transformative - the Internet, is a distributed network. So are peer to peer networks, such as the BitTorrent protocol, and also crypto-currencies, such as BitCoin. No one company or country can hold power over all of any of these networks.
Galloway however, argues that despite distributed networks being the freest network type, power is still controlled by the protocol itself. In order for a node to join a distributed network, it must play by the network's rules, which are defined in it's protocol. Therefore, power still exists, and it is held by the creators of the protocol.
It has been concluded that it is feasible for a distributed healthcare network to scale to provide planet-wide care (Kakouros, 2013). The socio-economic feasibility has not been demonstrated yet; there are very few precedents of using distributed networks in healthcare.
NHI
In order for any network to transfer information, there must be a standard way of identifying resources. In the case of an EHR system, the issue is if two nodes both have records for Alice Smith, how can we know if they're different people, or if they're the same person? Thankfully, the Ministry of Health thought of this. In New Zealand, all patients have a National Health Index (NHI), which is a number uniquely identifying them, across providers. This provides a perfect way to identify records.
Concepts
One unique network strategy has been used by 'cloud' storage provider, Storj (Storj Labs Inc., 2014). They provide a distributed cloud, powered by their user's computers. Files are encrypted, broken into pieces, then spread to other user's computers where they're stored. When a user wants to access a file, the file is downloaded from multiple users at once, which provides fast download speeds. The system has built-in redundancy - the file is stored multiple times in the network, to avoid malicious users.
This way your data is stored in the 'cloud' - but the cloud is created by the user's themselves.
Networks like this do have a potential to scale to huge size - they could technically support the storage requirements for a population's medical records. However, there is one issue - the encryption keys. Health records are a shared record - multiple parties need access to the one record at the same time, and they need to be added/removed as needed. In order to distribute the keys there needs to be a central point where all users access. This ultimately undermines the design of the decentralised system.
Software as a Service (SAAS) products have had an explosion in popularity since the availability of cheap, high-quality cloud computing services. Unlike software which you download to your computer then use, SAAS is used through a web browser. For example, New Zealand's own Xero is a SAAS product.
There is a lot of value in a fully cloud-based system. The first one is lowered IT costs. Software doesn't have to be installed and configured correctly, all your user needs to do is visit the website. A practice doesn't have to purchase a computer to be their practice's server. You as a user don't have to worry about backing up your data, as your provider should be doing that for you. And, it can be accessed anywhere a computer can get an Internet connection.
Within the context of primary care, a SAAS model can work. Healthcare companies such as Indici and Practice Fusion are betting on it (Indici, n.d.) (Practice Fusion, Inc., 2014). Their practice management systems are entirely online - they are fully cloud based. The main downside with systems like these is that if the Internet is down - your doctor can't use their software.
How often this occurs in New Zealand cities is debatable, particularly with the ability to use mobile Internet as a backup. However, looking at the context of designing a system to potentially be used outside of New Zealand primary care - it's not feasible. Medical professionals have to access and use patient data in situations where there is no network connectivity - or where ad-hoc networks have to be created separate to the Internet.
Instead, let's first focus on building a network for a singular institution, for example a doctor's practice. Lets say that a single node represents a server, which stores the practice's medical records. The node stores the user's login details, so they know who should have access to what record. This means that doctors (black dots) can login to the node to edit their patient's records.
Now, the bare minimum of duplication required to provide decent accessibility to data is two. One node physically running the pharmacy, and one running in the cloud. This means doctors can access records anywhere the Internet is available, or if the Internet is down in the practice they can still use them. However, if the cloud node has to be taken offline for maintenance, availability is highly affected. Data loss is also not likely with two nodes, but medical records are legally protected documents - loosing them would have ramifications. Therefore, I think the minimum optimal number of nodes a clinic should run is three, one physically, and two in the cloud, on different providers.
The nodes are duplications of each other - they all contain a complete copy of the records. This is called a 'Cluster'. If a record is changed in one node, it will be synced to the others when next available. This creates an eventually-consistent system, as in; eventually all nodes will have the same copy of the information. The clients (doctors) can access whatever node they like - and the other nodes provide backup connections (light grey). This way, if a node goes offline, is slow, or can't be accessed; they can switch to another node.
This provides a better system than traditional backups. The nodes don't sync on a schedule (eg once a day at midnight), changes are replicated throughout your network as they are made.
This is essentially a decentralised network. However, this is within the context of a singular health institution. What happens when our patient's records need to be accessed at the hospital?
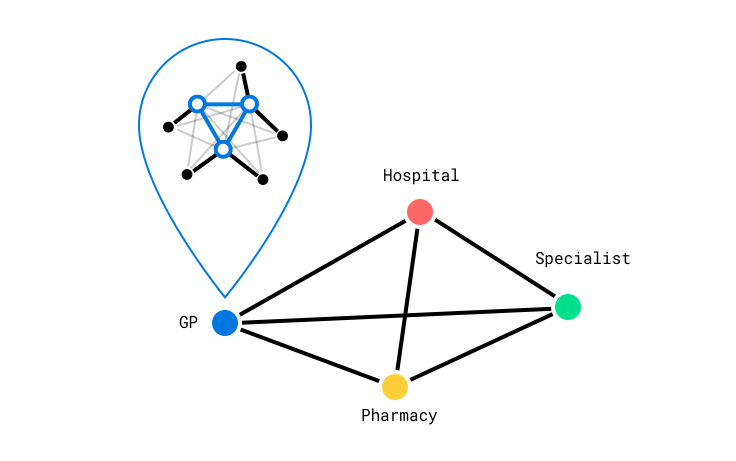
In this model, clusters are run by institutions (represented by fully coloured dots). Their clusters run independent of any other cluster - so they have full control over how they want to set up their nodes, and how they want to use them.
But then, clusters are connected together to form a distributed network, allowing institutions to collaborate on records. The key is that clusters will only share information with another institution, if it's relevant to that institution.
For example, our patient Alice visits the hospital, for an ankle injury. They prescribe her some medication and note it in the hospital's records. The hospital's cluster notices that Alice has updated her medication - and that other connected clusters also store Alice's medication information. So it sends the latest version of her medication list to her GP, her specialist, and her pharmacist. Now all institutions relevant to her care have the latest version of her information.
After her hospital visit, she goes to a follow up at her GP. Her GP makes notes in her visitation notes. The GP cluster notices the change - but no other connected cluster stores a copy of the visitation notes, so it doesn't update anybody else. In the same appointment she notes that her Eczema has been worse for the last few weeks. Her GP makes a note in the Dermatology section of her record. The GP's cluster sends this to her specialist (a dermatologist) but doesn't send it to her pharmacy, or the hospital - as that information isn't relevant to them.
I think this model works well for two reasons:
Independence. Despite institutions being connected in a network, they are not dependent on each other for service. If an institution is cut off from all of its connected institutions, it still has a full copy of the patient records it requires. The institution can continue to run independently, with full functionality.
Flexible robustness. This model can be as robust as needed. While this model could be run off just a single server, institutions can simply add more nodes to their cluster to increase availability, and robustness.
There is a caveat, more servers are potentially required overall, compared to a SAAS model.